
ICS-PA日记-PA4
边做边写的没有重新整理,全当记录一下。
Some reference
多道程序
上下文切换
Basic Idea:
- Context switching is the process stack switching
How to find Context of other processes? - Use a
cppointer (Context pointer) to record the Context structure’s position.
操作系统使用的是PCB结构 (process, control block)。每一个进程维护一个 PCB
我们首先来做内核线程。
创建内核线程上下文
创建内核线程上下文的函数是 kcontext(),在 abstract-machine/am/src/$ISA/nemu/cte.c 中定义
1 | Context *kcontext(Area kstack, void (*entry)(void *), void *arg) { |
kstack是栈的范围entry是内核线程的入口arg是内核线程的参数
在 kstack 的底部创建一个以 entry 为入口的上下文结构 Context c。
return value: 返回&c,该结构的指针。
1 | Context *kcontext(Area kstack, void (*entry)(void *), void *arg) { |
Stack frame 如下所示
1 | | | |
线程/进程调度
CTE 负责创建上下文和切换上下文。具体切换到,则是 OS 的工作。
我们用 schedule() 函数实现。用 current 指针,指向当前运行进程的 PCB,这样就可以用 current 决定接下来调度的进程。
1 | // nanos-lite/src/proc.c |
我们需要修改 trap.S 的汇编代码,使其完成上下文切换
1 | .globl __am_asm_trap |
做完这些之后,顺利输出 ?,不要惊慌,这是因为我们还没有处理 kcontext 的参数。
内核线程的参数
此处应该阅读 riscv32 的调用约定,查询 ABI 手册,来修改 kcontext() 函数,支持传参。
riscv32 ABI 规定,函数第一个参数用 a0 寄存器来传。这里是 GPR2 宏。
完成了切换。
OS 中的上下文切换
Nanos-lite
Nanos-lite 是我们的轻量级操作系统。
我们在其中实现上下文切换。
-
实现
context_kload -
完成
用户进程
创建用户进程上下文
和内核线程不同,用户西进程的代码都在用户区。我们在 AM 中实现 ucontext() 函数
然后再在 nanos-lite 中实现 context_uload 来调用 ucontext 加载用户上下文
- 设置 navy-apps 中的
_start,在libs/libos/src/crt0/start.S中。
Nanos-lite 和 Navy 作约定:Nanos-lite 把栈顶位置设置到 GPRx 中,然后由 Navy 里面的 _start 来把栈顶位置真正设置到栈指针寄存器中。
目前我们让Nanos-lite把 heap.end 作为用户进程的栈顶, 然后把这个栈顶赋给用户进程的栈指针寄存器就可以了.
目前用户栈的分配方式是直接将堆区末尾的一部分作为用户栈。
GPRx 即返回值寄存器,a0
mv sp a0
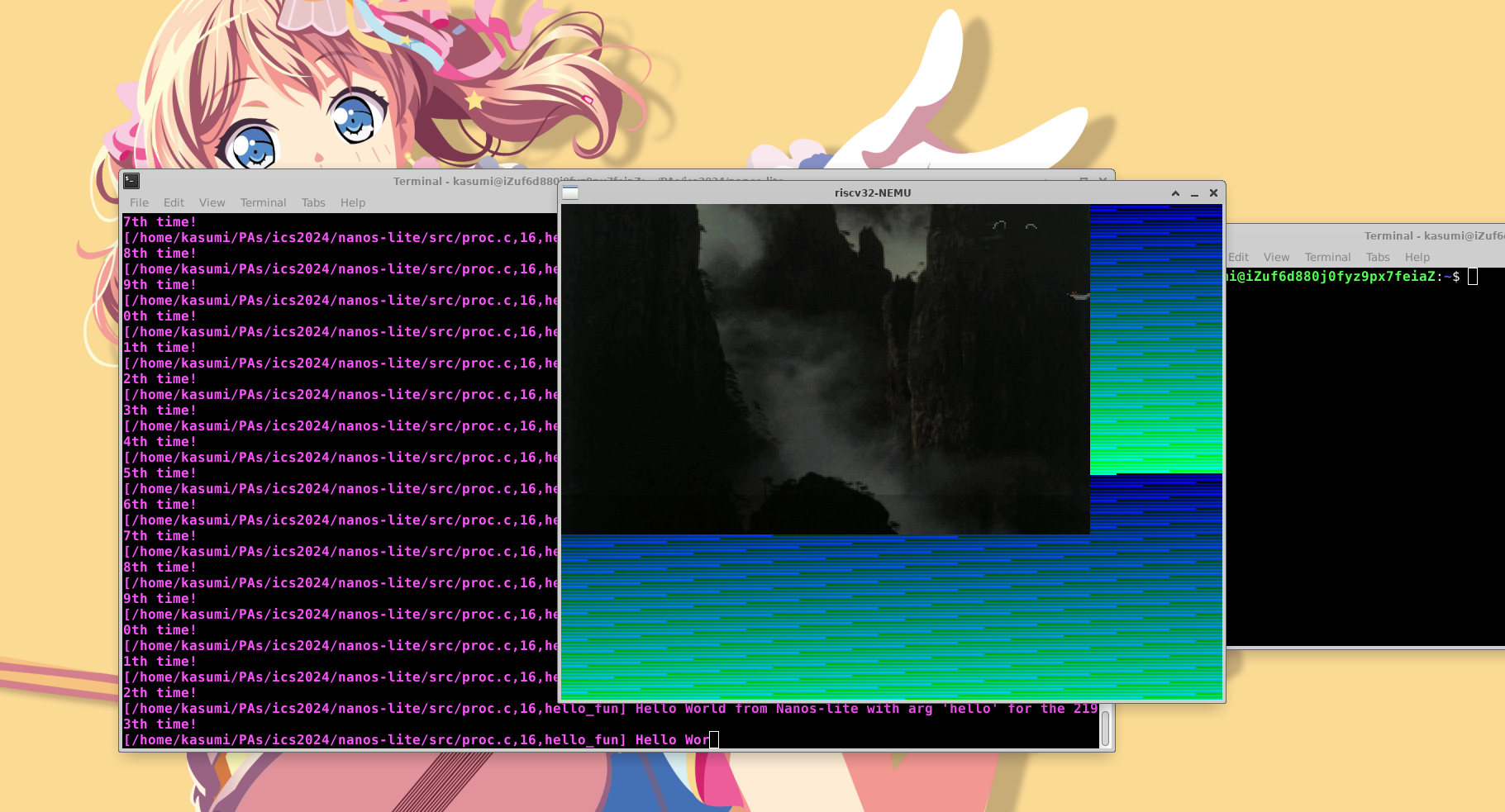
这样,可以在运行仙剑奇侠传的同时,运行 hello_fun
用户进程的参数
用户进程有自己的参数,参考 main() 完整的原型:
1 | int main(int argc, char* argv[], char* envp[]); |
我们要把 argc 的地址作为参数传递给 call_main,RISC-V 的 ABI 约定第一个参数是 a0。
需要修改 call_main 代码完成解析,这是一个简单的指针训练。
然后还需要修改 context_uload 的原型,使其支持参数。
回忆一下栈帧的知识,你现在需要把参数赋值到栈中。
所以要在 context_uload 函数中做出修改,把传给 context_uload 的参数,一个个压入用户栈。
现在用户栈初始情况不是一个空栈了,其栈帧如下:
1 | | | |
之前将 cp->GPRx 设置为 heap.end,其实是基于
- 用户栈为空。
- 用户栈从堆区末尾开始。
的假设。而现在,为了支持带参数的用户进程,我们必须做出修改了。
接下来尝试修改仙剑奇侠传的代码,如果识别到 --skip 就跳过开场动画。
1 | ! 473 if(!(strcmp(argv[0], "--skip") == 0)){ |
经过修改后,PAL 确实跳过了 trademark 界面。
但是一个个为应用程序设置参数,不显示。我们需要在 NTerm 中提供解析参数支持,就和真正的 linux 程序一样。
很自然想到系统调用 execve。实际上它的原型就是
1 | int execve(const char *pathname, char *const argv[], char *const envp[]); |
通过修改 syscall.c 中系统调用,加载参数调用 execve 即可
最后在 nterm 增加了解析功能。
1 | static void sh_handle_cmd(const char *cmd) { |
现在可以通过 nterm 输入 /bin/pal --skip 实现跳过 trademark 启动 pal 了
超越容量的界限
和分段机制相比, 分页机制更灵活, 甚至可以使用超越物理地址上限的虚拟地址. 现在我们从数学的角度来理解这两点. 撇去存储保护机制不谈, 我们可以把这分段和分页的过程分别抽象成两个数学函数:
1 | y = seg(x) = seg.base + x |
把虚存管理抽象为 VME
虚存的本质是一个映射(VA -> PA),虚存管理的本质是维护这个映射。
有以下的 API
1 | // 创建一个默认的地址空间 |
地址空间 AddrSpace 的定义为:
1 | typedef struct AddrSpace { |
我们还需要对 ucontext 函数进行修改。
vme_init :定义在 abstract-machine/am/src/riscv/nemu/vme.c 中,负责初始化 VME 环境。
vme_init()会通过map()来填写内核虚拟地址空间的映射. 这些映射十分特殊, 它们的va和pa是相同的, 我们将它们称为"恒等映射"(identical mapping).——PA 手册
我们使用 risc-v,需要硬件对 VME进行处理。实际上 vme.c 中的 set_satp 就是一条 ASM inst
1 | static inline void set_satp(void *pdir){ |
终于要回到 NEMU 做点事情了。
注意及时 assertion!
实现isa_mmu_translate
参考手册 (4.3 Sv32: Page-Based 32-bit Virtual-Memory Systems)实现
1 | paddr_t isa_mmu_translate(vaddr_t vaddr, int len, int type); |
对内存区间为[vaddr, vaddr + len), 类型为type的内存访问进行地址转换. 函数返回值可能为:
pg_paddr|MEM_RET_OK: 地址转换成功, 其中pg_paddr为物理页面的地址(而不是vaddr翻译后的物理地址)MEM_RET_FAIL: 地址转换失败, 原因包括权限检查失败等不可恢复的原因, 一般需要抛出异常MEM_RET_CROSS_PAGE: 地址转换失败, 原因为访存请求跨越了页面的边界
这个函数在NEMU层面实现翻译虚拟地址到物理地址页面地址。
RV32在 satp 寄存器中存储PPN
我们对 satp 新增的定义在 nemu/src/isa/riscv32/include/isa-def.h" 中
1 |
![[Pasted image 20260112220229.png]]
1 | | MODE | ASID | PPN | |
SV 32 的虚拟地址有 32 bit,
1 | // virtual address |
而物理地址 PA 有 34 位
1 | // physical address |
PPN 实际我们是从 satp 获得的。定义一个宏来获得 PPN
The RISC-V Instruction Set Manual, Volume II: Privileged Architecture | Five EmbedDev
详细的转换过程可以阅读。
RV 32 的 Sv 32 虚拟地址机制采取二级页表的形式。
实现 VME 中的 map
这个是[[#实现isa_mmu_translate]] 的逆过程。
VME 里的 map 定义在 abstract-machine 中,具体来说
1 | void map(AddrSpace *as, void *va, void *pa, int prot); |
它用于将地址空间 as 中虚拟地址 va 所在的虚拟页, 以 prot 的权限映射到 pa 所在的物理页. 当 prot 中的present位为 0 时, 表示让 va 的映射无效. 由于我们不打算实现保护机制, 因此权限 prot 暂不使用.
map() 是VME中的核心API, 它需要在虚拟地址空间 as 的页目录和页表中填写正确的内容, 使得将来在分页模式下访问一个虚拟页(参数 va)时, 硬件进行page table walk后得到的物理页, 正是之前在调用 map() 时给出的目标物理页(参数 pa). 这再次体现了分页是一个软硬协同才能工作的机制: 如果 map() 没有正确地填写这些内容, 将来硬件进行page table walk的时候就无法取得正确的物理页.
在分页机制下运行用户程序
几个需要更新的点:
- Navy 中
make需要加VME=1参数,以映射到正确位置 - Nanos-lite 中,
context_uload需要在开头调用protect() - 需要对用户栈进行处理
1 | struct Context { |
void *pdir 是一级页表的物理地址
1 | [/home/kasumi/PAs/ics2024/nanos-lite/src/loader.c,40,loader] opening the fle: /bin/dummy |
定位到了 isa_mmu_translate 出发了错误。
1 | [/home/kasumi/PAs/ics2024/nanos-lite/src/loader.c,116,loader] ELF entry at 0x40000420 |
因此 Loader 的逻辑没问题。可能是用户 stack 转移的问题
这段手册的提示直接点出了你目前 Segmentation Fault 的核心症结:你的 sp 寄存器里装的是物理地址(PA),但在分页模式下,CPU 需要的是虚拟地址(VA)。
结合你之前的 GDB 状态 gpr[2] (sp) = 0x82649f40,这显然是一个物理地址
在 am 中 trap.S 中做出修改,#define CONTEXT_SIZE ((NR_REGS + 3 + 1) * XLEN) ,增加对 pdir` 的支持
这里最后发现是 context_uload 在调用 ucontext 时候,没有传入 pcb->as 导致地址空间没有正确设置。多加 assert 啊还是要
实现 mm_brk()
这里真是埋了不少坑啊,因为 PA 3 省略了很多实现,包括 brk 堆顶的维护,malloc 只是增加了堆顶,而没有做其他检查。在实现 VME 之后要忙活很多
发现了极小的内存访问,发现是 navy-apps 中的 libos 库实现的有问题。我们借助 sbrk 的封装,实现 brk,但是系统调用角度 SYS_brk 应该传入的不是增量。
1 | void *_sbrk(intptr_t increment) { |
注意处理 mm_brk 的边界对齐问题
我们用户程序有一份内核映射(实际上是 0x80000000 - 的恒等映射),具体来说在 protect() 函数中绑定,所以不需要切换
1 | void protect(AddrSpace *as) { |
发现用户栈 0x7ffffcac 从没有被 map 过
1 | Walking page table: vaddr=80001bb8, pt1_entry=825b5000 |
检查 satp,发现 0x7ffffcac 的 satp 和前面的不一样,证明 schedule 时候地址空间发生了异变
1 | [/home/kasumi/PAs/ics2024/nanos-lite/src/proc.c,58,schedule] Schedule from current 1 -> next 1 |
经检查也是 schedule 之后出了问题
我们发现 schedule 调用了
1 | void __am_get_cur_as(Context *c) |
但是我起初的代码没有加 c->pdir!=NULL 的检查,导致我对内核的 c->pdir 的 NULL 标记失效,从而错误的切换了地址空间
之后又出现了 Conflict Map 问题,经检查又是老生常谈的 mm_brk 的重复映射。这次是因为我 max_brk 维护直接写得 max_brk = brk(usr's parameter) 但是 navy-apps 中通过 sbrk(int increment) 做 SYS_brk 的系统调用的时候,有时候是负值,这就导致我检查边界有问题的重复映射,修改为 max_brk = max(max_brk, brk) 解决了这个问题。现在用户程序和内核程序可以同时运行了。
![[Pasted image 20260214004918.png]]
来自外部的声音
抢占分时系统
这里我按部就班,按照手册,很顺利的完成了但却不然,遇到了很奇怪的 bug,从内核程序切换到 PAL 之后,会过一段时间报一个 access addr: 0 的错误
这显然不是 VME 的锅了(因为分时只改变了我们 schedule 的时机,从 yield 到外部中断 timer-interrupt),经过一番痛苦的 debug(即从新增的代码寻找可能得影响),发现是 abstract-machine 层的遗留问题:正确处理 mepc 更新的时机(+=4 来跳过 ecall,但是外部中断不用跳!)
在 RISC-V 中,异常 (Exception) 和 中断 (Interrupt) 对 mepc 的处理要求是不同的:
-
同步异常 (如
ecall):mepc指向的是ecall指令本身。如果你不加 4,mret返回后会再次执行ecall,陷入死循环。所以yield和syscall必须+4。 -
外部中断 (如
timer interrupt):mepc指向的是被中断打断的那条指令。这条指令还没有被执行完(或者还没开始执行)。处理完中断后,你应该原封不动地返回到这条指令。如果你在这里+4,你就跳过了用户程序的一条指令。
![[Pasted image 20260215012336.png]]
这是一个 PA 3 留下的坑:即 RISC-V 在何种时机更新 PC? 在 [[ICS-PA3 note#系统调用(Nano-lite 层)]] 我们曾经提到过:要在正确的地方做出更新 mepc, 当时我只是简单的在 am/src/riscv/nemu/cte.c : __am_irq_handle 的最前面做出更新
但是,当我们引入 外部中断 之后,事情变得不一样:外部中断并不是靠一条 ecall 指令来完成自陷 (trap) 的,所以不需要跳过这一条指令(还记得 PA 3,你没有跳过指令,然后 yield-test 会一直循环打印吗?)。
修正这个问题后,PA 4-3 的第一部分通过
用户栈切换
而为了实现上述功能, 我们又需要解决如下问题:
- 如何识别进入CTE之前处于用户态还是内核态? -
pp(Previous Privilege) - CTE的代码如何知道内核栈在什么位置? -
ksp(Kernel Stack Pointer) - 如何知道将要返回的是用户态还是内核态? -
np(Next Privilege) - CTE的代码如何知道用户栈在什么位置? -
usp(User Stack Pointer)
1 | void __am_asm_trap() { |
在我们的实现中,我们把
np映射为c->npksp映射为mscratch寄存器sp映射为gpr[sp]
由于 ksp 总是在 pp == USER 的时候被使用,且 ksp 的值肯定不为 0,所以可以用 ksp == 0 表示 pp == KERNEL
- 若当前位于用户态, 则
ksp的值为内核栈的栈底 - 若当前位于内核态, 则
ksp的值为0
根据伪代码修改 trap.S 即可
Storing a PPN in satp, rather than a physical address, supports a physical address space larger than 4 GiB for RV32.The satp.PPN field might not be capable of holding all physical page numbers. Some platform standards might place constraints on the values satp.PPN may assume, e.g., by requiring that all physical page numbers corresponding to main memory be representable. |



