
金融大数据处理技术(FBDP) lab1 日志
实验概况
本实验是南京大学计算机金融实验班 2023 级,金融大数据处理技术 (FBDP) 的 Hadoop 实验 1,主要是熟悉环境配置。
- 设备:
Macbook Pro M4, ram: 24g docker+ubuntu 22.04hadoop-3.4.2-aarch64
任务 1
环境准备
我们先用 docker 部署一个单机伪分布模式。
- 在终端 (我使用
iTerm2 -zsh) 输入docker exec -it <container_id> /bin/bash进入容器 sudo apt install安装vim以修改设置docker cp命令将宿主机Mac下载好的Hadoop文件传输,解压,配置环境变量。vi ~/.bashrc
1 | export HADOOP_HOME=/usr/local/hadoop |
source ~/.bashrc
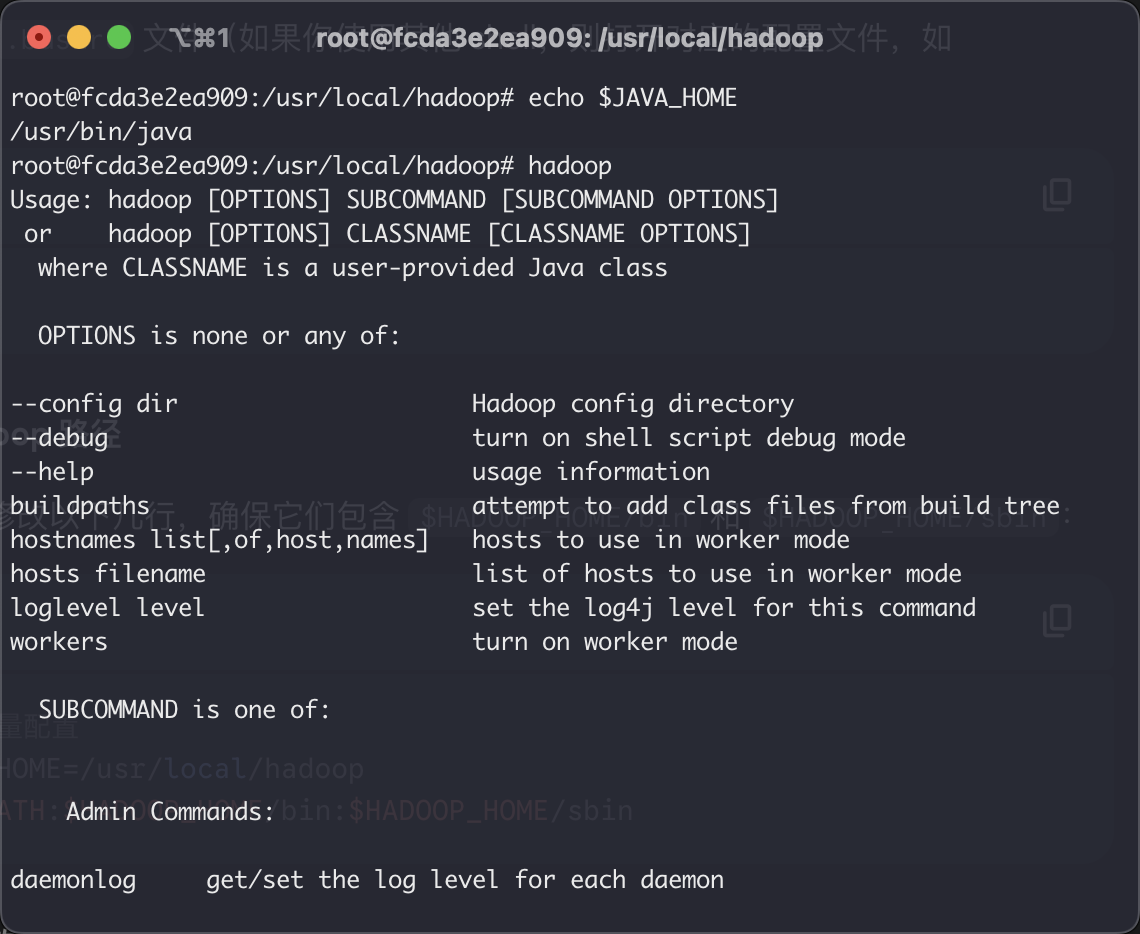
- 该图片说明 hadoop 已经配置完毕环境。
配置 Hadoop
该配置发生在 etc/hadoop 目录。参照老师的讲义。
对于各文件的意义,可参考:
-
core-site.xml:核心配置文件,定义了集群是分布式,还是本机运行 -
hdfs-site.xml:分布式文件系统的核心配置,决定了数据存放路径,数据的副本,数据的 block 块大小等等 -
mapred-site.xml:定义了 mapreduce 运行的一些参数 -
yarn-site.xml:定义 yarn 集群 -
slaves:定义了从节点是哪些机器 datanode,nodemanager 运行在哪些机器上 -
hadoop-env.sh:配置 jdk 的 home 路径 -
hadoop-env.sh- 配置
export JAVA_HOME
- 配置
-
core-site.xml- 配置 HDFS 的
NameNode地址端口
- 配置 HDFS 的
1 | <configuration> |
hdfs-site.xml- 配置 HDFS 副本数量和数据存储目录
1 | <configuration> |
mapred-site.xml- 配置 MapReduce 框架,使用 yarn
yarn-site.xml- 重要:配置 Yarn 的
ResourceManager地址
- 重要:配置 Yarn 的
1 | <configuration> |
workers- 指定主机名(单机伪分布填写本机)
配置无密码登录 SSH
首先安装 ssh 服务
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa- 然后复制该密钥
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
开始测试
- 启动 HDFS 服务
1 | root@fcda3e2ea909:/usr/local/hadoop# start-dfs.sh |
- 启动 YARN 服务
1 | start-yarn.sh |
jps命令查看进程是否都启动
1 | root@fcda3e2ea909:/usr/local/hadoop# jps |
- 使用
docker cp复制目标example.txt文件到docker主体上 - 然后,上传该文件到 HDFS
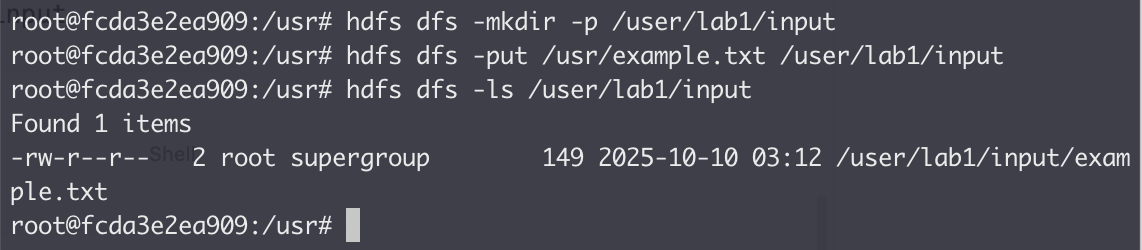

实验数据说明
本试验运行 wordcount ,输入为一段 txt 文本,其内容为:
1 | Hadoop hadoop mapreduce zookeeper |
运行程序
yarn jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar wordcount /user/lab1/input /user/lab1/output
输入后,机器开始处理。
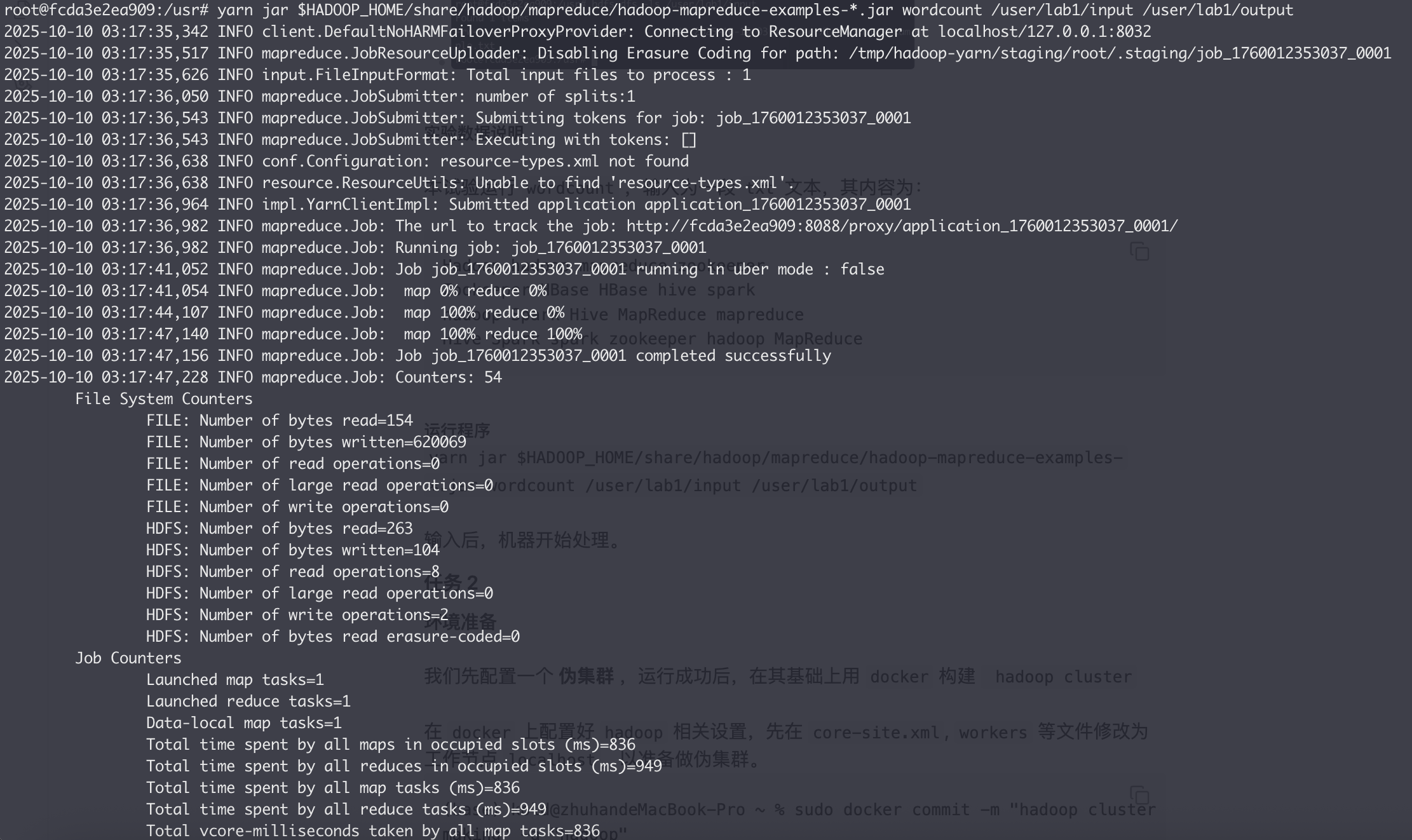
Job Counters(作业总体资源使用)
Launched map tasks=1 Launched reduce tasks=1 Data-local map tasks=1
任务共启动了一个 Map、一个 Reduce,都运行在数据本地节点(data-local),性能最佳。
Total time spent by all map tasks (ms)=836 Total vcore-milliseconds taken by all map tasks=836
Map 阶段用时约 836 ms,Reduce 阶段用时约 949 ms。说明任务轻量。
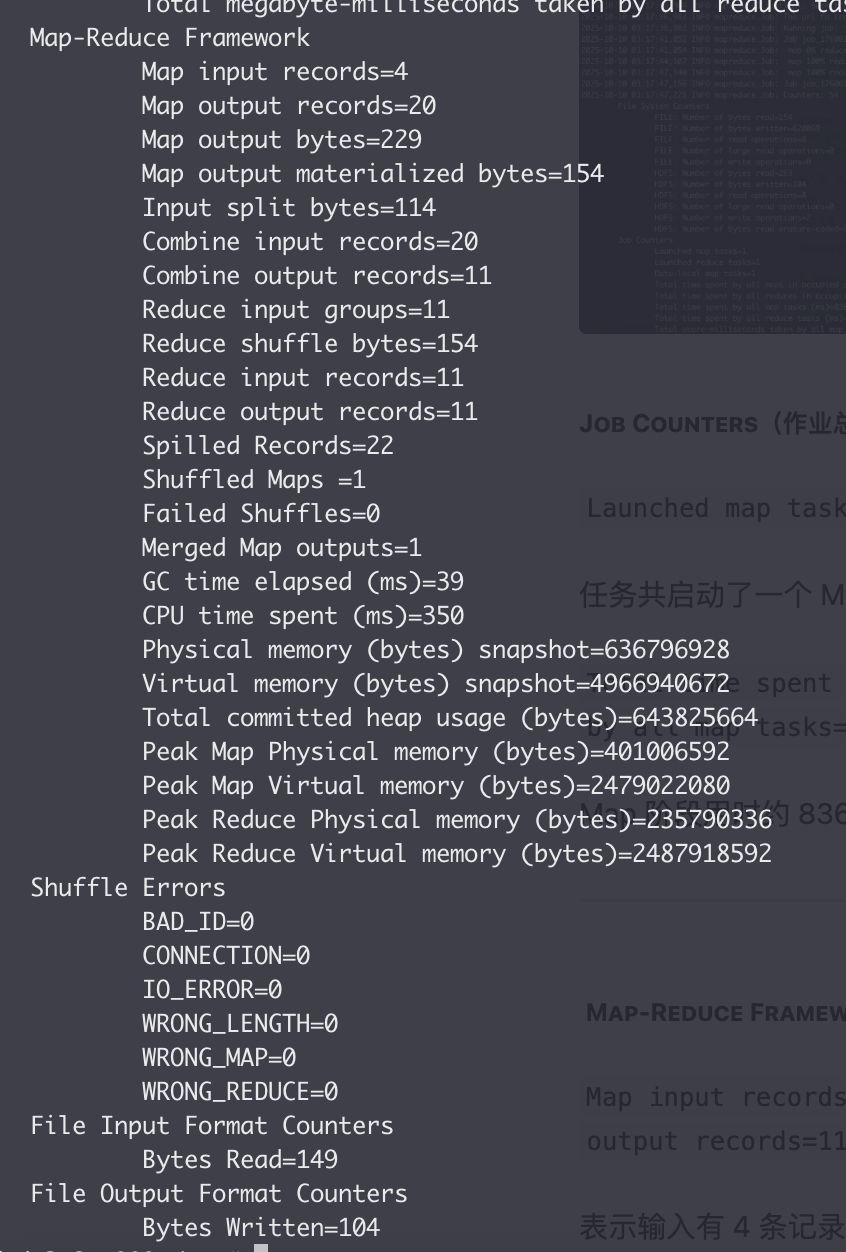
Map-Reduce Framework(任务统计)
Map input records=4 Map output records=20 Combine input records=20 Combine output records=11 Reduce output records=11
表示输入有 4 条记录(比如 4 行文本),经过 Map 产生 20 个键值对,Combiner 聚合为 11 个中间结果,最终 Reduce 输出 11 条结果。
Reduce shuffle bytes=154
Shuffle 阶段传输了 154 字节数据(Map 输出传给 Reduce 的中间数据量)。
查看结果
查看 HDFS 输出目录的内容:
1 | hdfs dfs -ls /user/lab1/output |
看到一个名为 _SUCCESS 的空文件和一个名为 part-r-00000 (或类似名称) 的文件,后者包含计数结果。
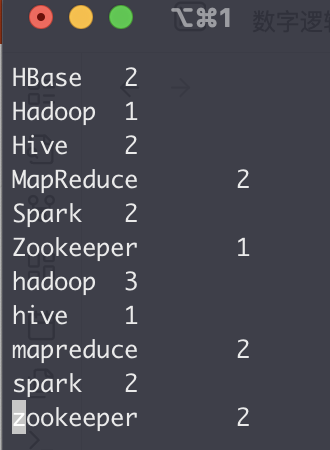
我们下载到本地打开
-

-
-
结果正常。
-
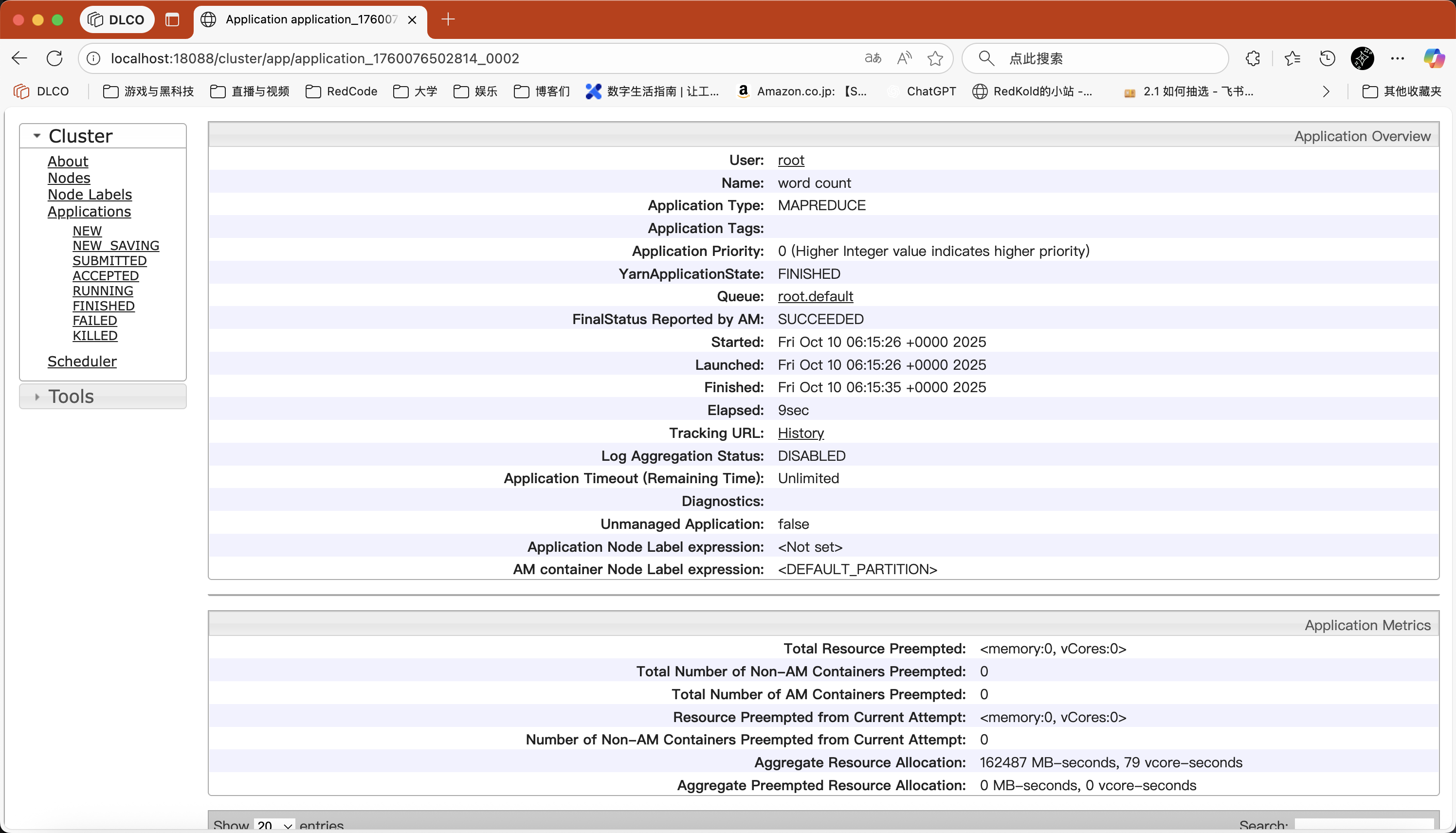
登录 web 界面查看
mapreduce工作节点的结果 -
任务 2
环境准备
我们先配置一个 伪集群(在任务 1 实际已经完成) ,运行成功后,在其基础上用 docker 构建 hadoop cluster
在 docker 上配置好 hadoop 相关设置,先在 core-site.xml, workers 等文件修改为工作节点 localhost,以准备做伪集群。
1 | (base) kold@zhuhandeMacBook-Pro ~ % sudo docker commit -m "hadoop cluster making" -a "hadoop" 4ff9cb430765b08ce8f3c088cc370a0f349b6f4f3ec0cd0de46b3e3aead010b5 hadoop-cluster-image:v1 |
配置好 ubuntu hadoop 镜像,docker commit 来配置集群,封装成 images,并导出。
- 使用如下命令配置
docker端口映射并启动
1 | docker run -it \ |
-
启动成功,进入 web UI 页面查看
-
我们需要输入命令上传,这涉及到基本的 Hadoop 操作
之后,运行 hadoop 任务
- 运行任务的通用格式
yarn jar <path/to/examples.jar> <program_name> <input_path_on_hdfs> <output_path_on_hdfs>
- 我们使用的
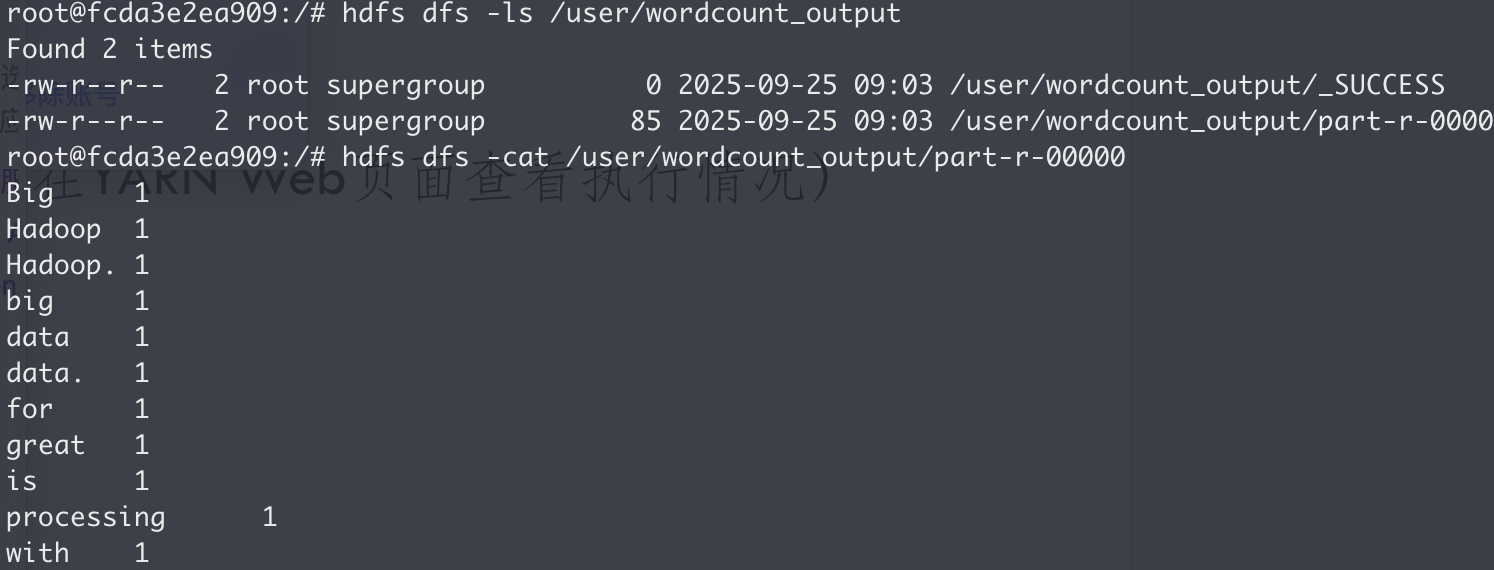
1 | yarn jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar wordcount /user/wordcount_input /user/wordcount_output |
wordcount: 任务的名称,告诉 JAR 包运行哪个示例程序。/user/wordcount_input: 我们在步骤一中创建的 HDFS 输入路径。/user/wordcount_output: MapReduce 任务将结果写入的 HDFS 输出路径。 注意:此目录在运行前不能存在!
问题和解决问题
Port Conflict
- 端口冲突:
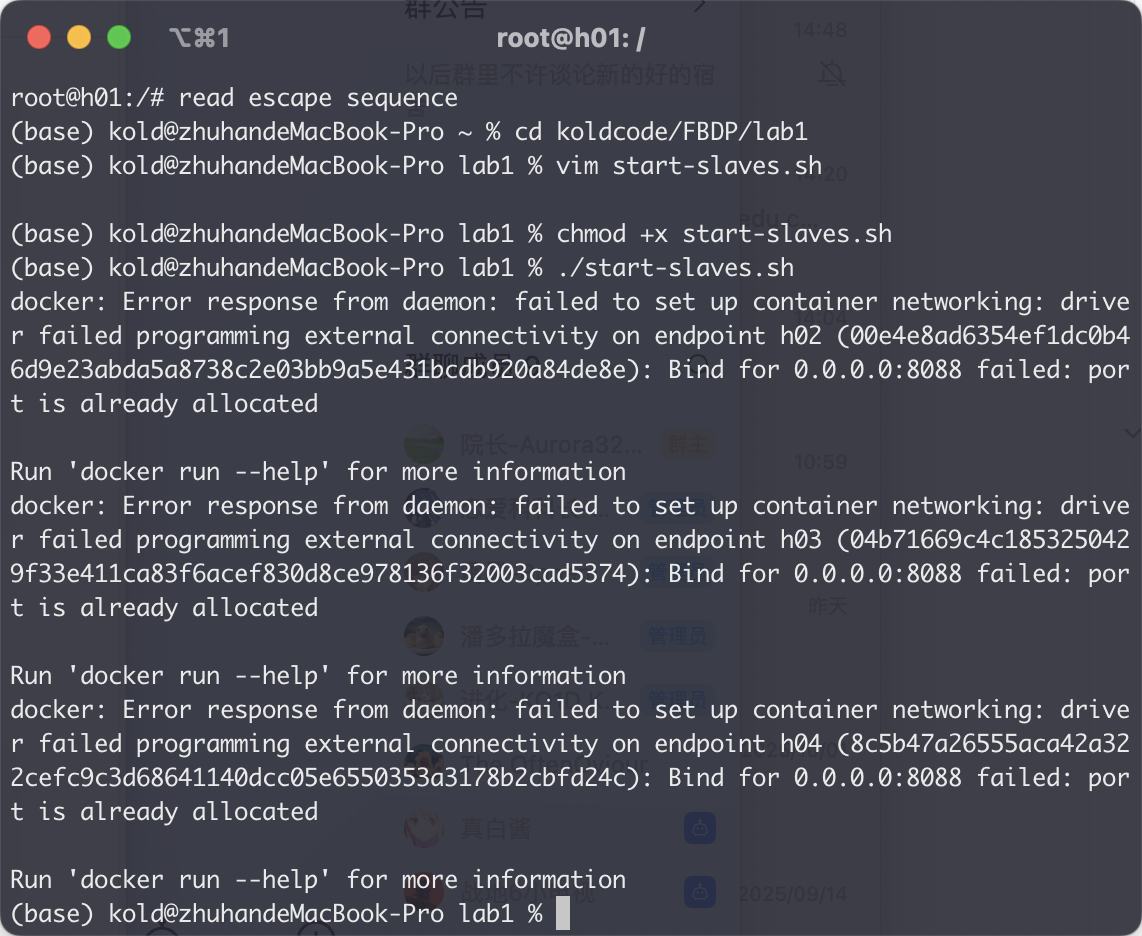
- 解决:
- 启动的时候,
-p [x]8088:8088,其中[x]为h[x]的序号。 --network hadoop的作用是创建一个 docker 的桥接网络 (Bridge), 由于我们在[[#配置无密码登录 SSH|第一部分的SSH配置]]中已经完成了相关配置,这里不需要额外配置 ssh 了。(各个容器共用一套密钥)
- 启动的时候,
1 | docker run -it --network hadoop -h "h02" --name "h02" -p 29870:9870 -p 28088:8088 hadoop-cluster-image:v2 /bin/bash |
- 经测试,
h1可以通过ssh登录到其他节点 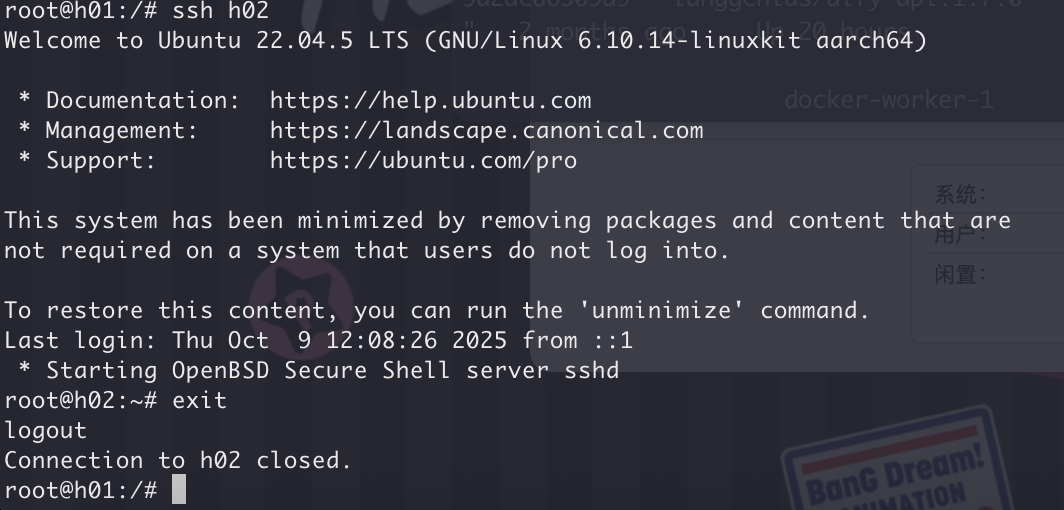
格式化
由于导出容器是测试过单机伪分布的,其保存了一些 DataNode 的旧集群的元数据。
1 | rm -rf /home/hadoop3/hadoop/tmp/dfs/data/* |
- 清空之后,重启主节点,解决了问题
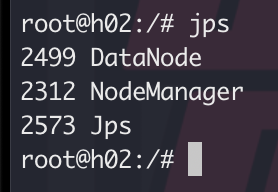
启动容器集群
使用 hadoop dfsadmin -report 查看主节点报告信息,可见启动成功。
1 | root@h01:/usr/local/hadoop# hadoop dfsadmin -report |
- 也可以在
localhost:9870查看 web ui 的信息 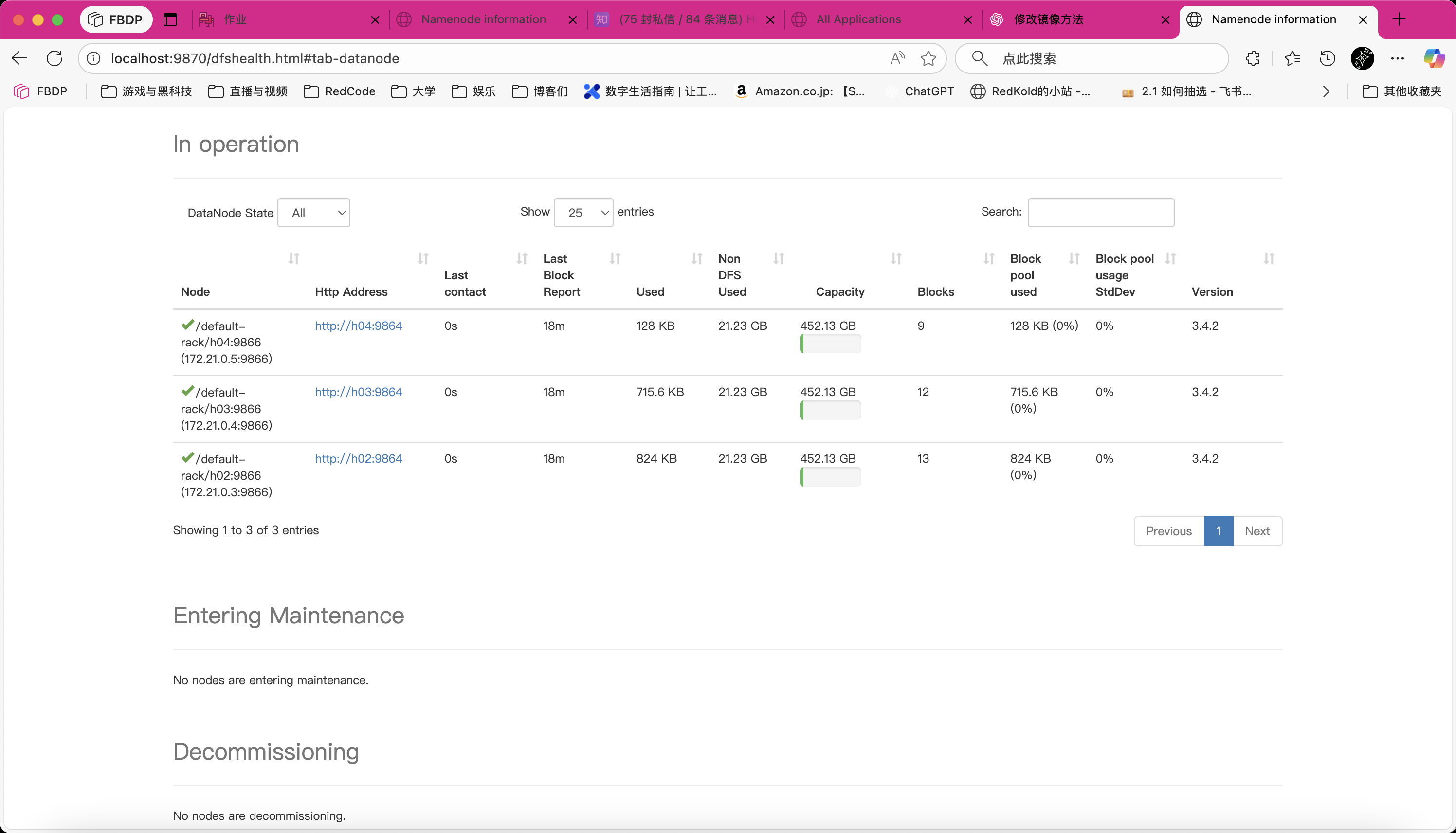
运行程序
- 首先,把输入文件(本实验要求
$HADOOP_HOME/etc/hadoop/*.xml)传输到hdfsroot@h01:/usr/local/hadoop/etc/hadoop# hdfs dfs -put ./*.xml /user/lab1_2/input
- 然后,运行官方
jar
1 | yarn jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep /user/lab1_2/input /user/lab1_2/output 'dfs[a-z.]+' |
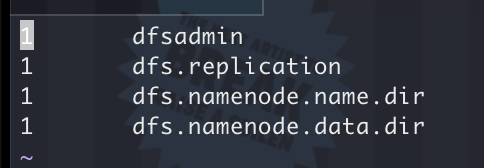
查看结果
- 同理,下载下来,查看文件
1 | root@h01:/usr/dev/lab1# hdfs dfs -ls /user/lab1_2/output |
- 得到
1 | 1 dfsadmin |
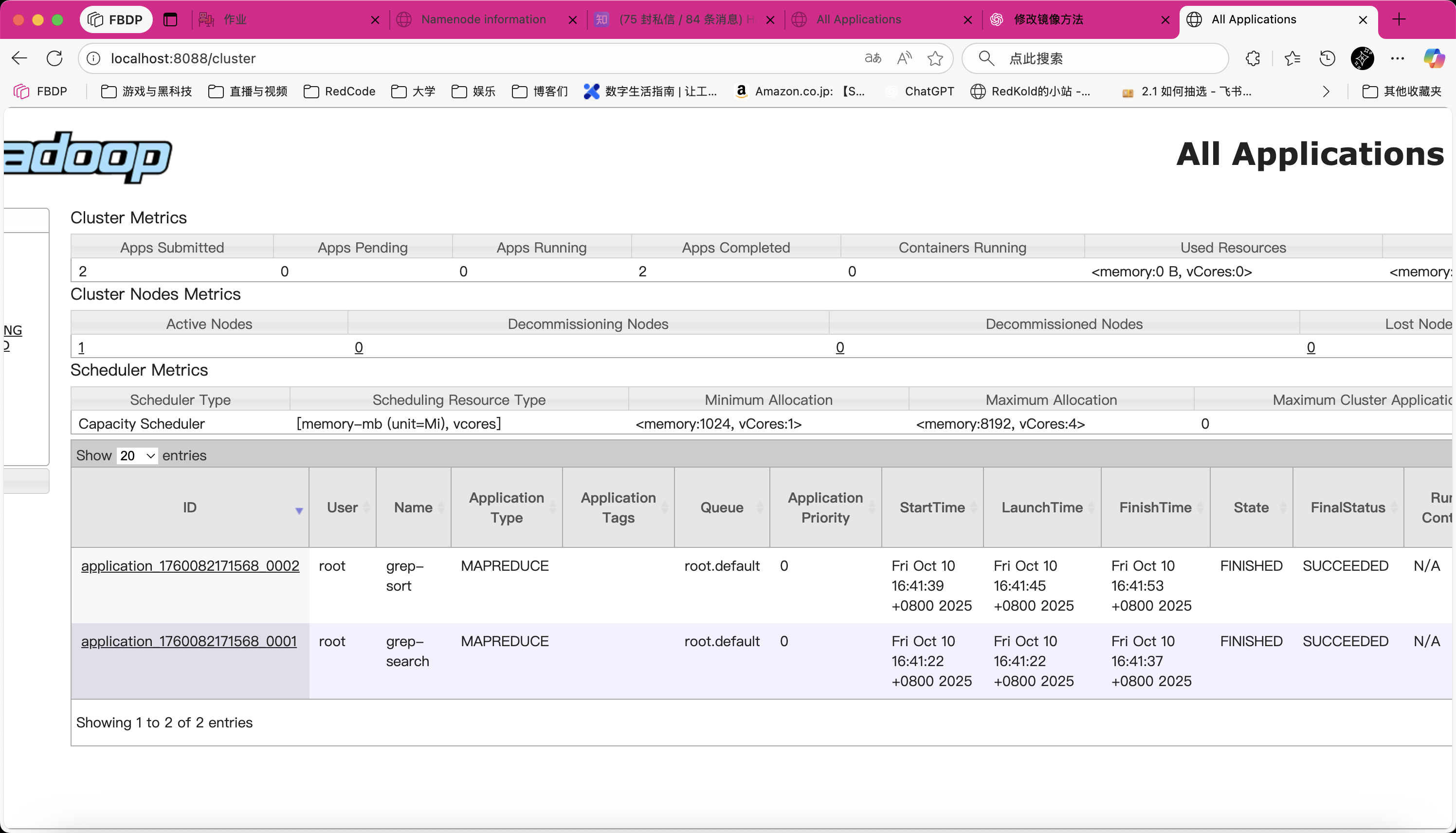
- 去
web ui查看结果
实验收获
本次实验,进一步熟悉了 linux 的命令行操作,熟悉了 docker 的进阶用法(以前只会简单应用安装,现在学习了导出自己写好的镜像),体会到了 docker 抽象的魅力和并行计算的乐趣。
期间遇到的问题,多数是 环境配置 问题,通过 AI Agent 和 Google 的帮助能得到比较好的解决。仰赖——
- 提问的智慧
- 对报错
log的耐心阅读 - 老师讲义的帮助
- 无私的论坛奉献者
关于问题的解决,可参见[[#问题和解决问题]] 部分。



