1. 架构设计¶
系统架构:¶
- 前端:基于React框架,提供用户界面,负责风险评估问卷、投资建议展示等交互功能。
- 后端:采用Flask作为API服务框架,提供接口支持用户管理、投资建议和数据处理。
- 数据层:使用MySQL存储用户数据和市场数据
数据流:¶

2. 系统功能模块设计¶
核心功能模块:¶
模块交互矩阵¶
| 模块名称 | 依赖模块 | 数据接口 | QPS(Queries Per Second)限制 | 接口功能说明 |
| 用户界面模块(UI) | 用户管理模块(UM) | /api/ui/dashboard | 500 | 获取用户的投资组合与收益曲线等数据,支持响应式布局的动态渲染 |
| 数据处理模块(DT) | /api/ui/recommendations | 200 | 接收个性化投资策略报告或产品推送数据 | |
| 用户管理模块(UM) | 数据隐私处理模块(PR) | /api/users | 300 | 用户信息维护,包括用户的注册(POST)、登录(POST)、信息修改(PUT)、查询(GET)、注销(DELETE)等操作 |
| 路由系统 | /api/auth | 100 | 用户身份认证,依赖路由系统分配权限 | |
| 数据隐私处理模块(PR) | 用户管理模块 | /api/privacy/risk-profile | 150 | 设计用户风险承受能力测试,并存储用户风险承受能力测试结果,返回风险等级(POST/GET) |
| 敏感数据加密 | AES加密中间件 | 200 | 对用户的敏感信息加密,诸如密码、身份证号、手机号码等信息 | |
| 权限控制服务 | JWT令牌验证中间件 | 200 | 控制接口访问权限,例如尚未登录的用户不能访问投资组合、收益曲线等数据 | |
| 数据处理模块(DT) | 数据隐私处理模块(PR) | /api/data/analysis | 200 | 接收清洗后的多源异构数据,基于大语言模型生成投资建议(POST) |
| AI引擎 | /api/data/LLM | 50 | 调用大语言模型进行因子挖掘和金融风控算法训练(异步接口) | |
| WebSocket | /ws/updates | 300 | 实时推送资产配置优化建议或分析进度(如文件分析中的Web Worker状态同步) |
关键接口说明¶
-
用户界面模块 (UI):
-
/api/ui/dashboard
依赖用户管理模块(UM)获取用户基础信息,依赖数据处理模块(DT)获取投资数据。
返回格式:JSON(包含收益曲线、持仓分布等图表数据)
- /api/ui/recommendations
接收数据处理模块(DT)生成的策略报告,前端通过Web Worker解析后渲染为可读性内容
-
用户管理模块(UM):
-
/api/users
实现RESTful风格接口,支持用户注册(POST)、登录(POST)、信息修改(PUT)、查询(GET)、注销 (DELETE)。
数据字段:username、password(通过AES加密中间件加密)、risk_level(来自PR模块)等
-
数据隐私处理模块(PR):
-
/api/privacy/risk-profile
用户提交风险评估问卷后,调用此接口并划分风险等级(低low-中mid-高high)
数据字段:user_id、questionnaire_data、risk_level。
-
数据处理模块(DT):
-
/api/data/LLM
异步接口,调用AI引擎进行模型训练,返回任务id供前端轮询进度
- /ws/updates
通过WebSocket实时推送分析结果(如文件分析完成通知)或策略更新。
2.1 前端功能模块¶
-
用户界面模块 (UI):
- 提供简洁的界面,展示核心功能入口。
- 仪表盘设计,直观展示用户投资组合与收益曲线。
2.2 后端功能模块¶
2.2.1 后端功能模块细化表¶
| 主模块 | 子模块 | 接口示例 | 功能描述 |
| 用户管理 (UM) | 用户信息维护 | POST/api/auth/register POST/api/auth/login |
实现用户注册登录系统,即维护用户数据库的增、删、改、查。 |
| 数据隐私管理 (PR) | 用户画像 | POST/api/privacy/risk-profile | 设计并引导用户填写风险承受能力测试(年龄/收入/投资目标),评估投资偏好,划分风险等级(低/中/高)。 |
| 敏感数据加密 | AES加密中间件 | 对用户密码、身份证号、手机号等字段进行加密存储 | |
| 权限控制服务 | JWT令牌验证中间件 | 控制接口访问权限(如未登录用户禁止访问投资建议) | |
| 基金数据清洗 | POST/api/data/funds | 处理基金净值数据 | |
| 一体化数据分析 | POST/api/data/analysis | 基于大语言模型提示学习和符号化因子挖掘的智能决策研究,生成投资建议 | |
| 模型服务 | POST/api/dataLLM | 基于异构数据学习的金融风控算法,生成适合大模型训练的数据 | |
| 个性化投资策略 | POST/api/data/report | 大模型返回资产的组合管理与优化配置建议数据,本模块将其生成可读性良好的报告或具体的产品推送信息 | |
| ### 2.2.2 模块协作关系图 |
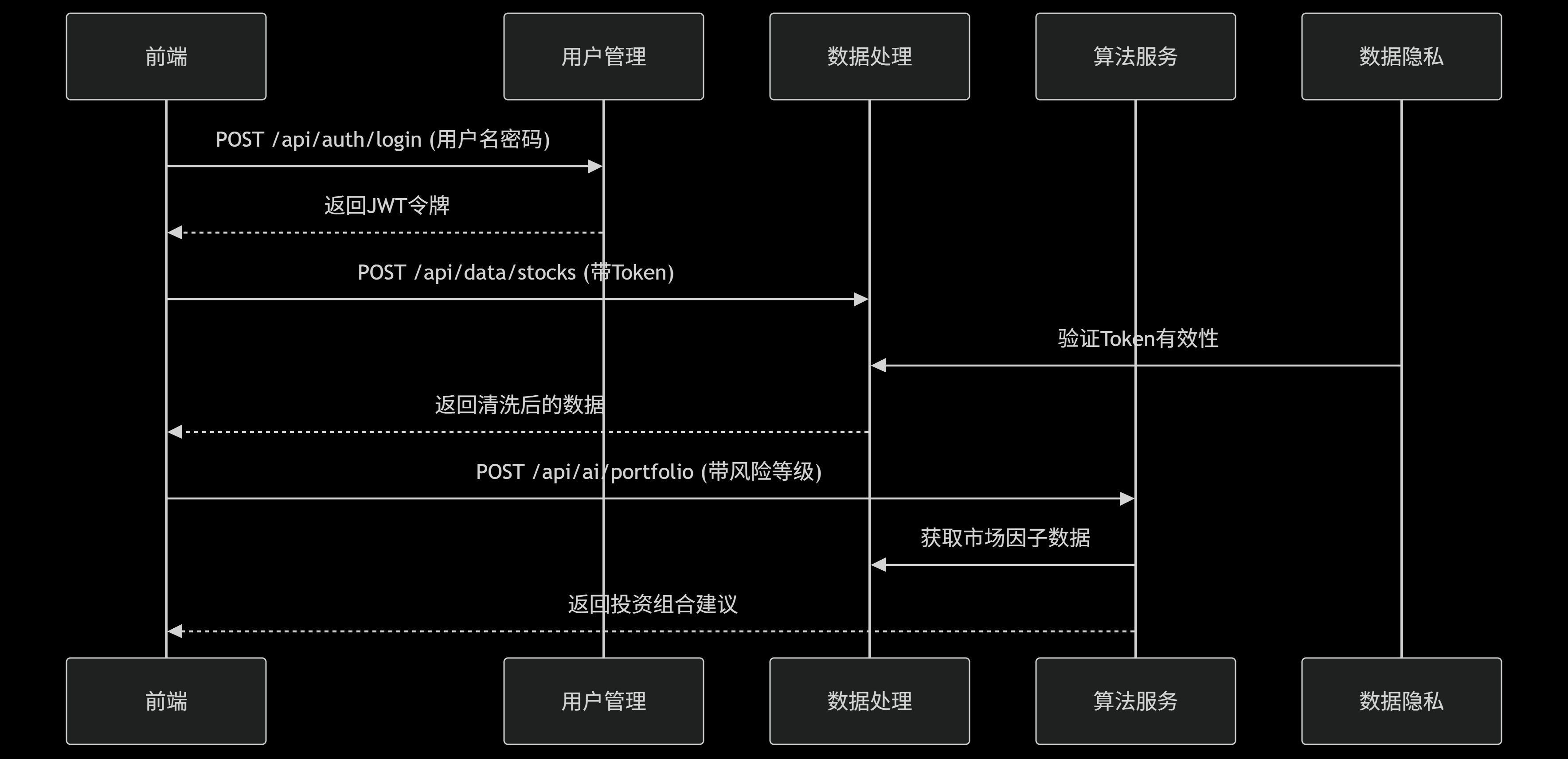
3. 界面设计¶
页面功能设计¶
-
主页:
- 提供各大功能入口
- 投资组合推荐和动态优化展示
- 提供「我的信息」页面入口
-
风险评估页面:
- 引导用户完成问卷,记录年龄、收入、投资目标和风险态度。
- 输出用户风险等级。
-
投资建议页面:
- 基于数据分析生成投资建议
- 借助LLM将投资建议转化为报告,呈现给用户
-
仪表盘:
- 以图表形式展示市场趋势
-
我的信息:
- 显示用户信息
- 支持修改用户昵称等信息
4. 数据库设计¶
MySQL 集合规范¶
用户表(user)¶
| 字段 | 类型 | 说明 |
| user_id | INT AUTO_INCREMENT PRIMARY KEY | 用户ID [主键] |
| username | VARCHAR(255) | 用户名 |
| VARCHAR(255) | 用户邮箱地址 | |
| password_hash | VARCHAR(255) | 加密存储的密码 |
| risk_level | INT | 用户风险等级 |
市场数据表(market_data)¶
| 字段 | 类型 | 说明 |
| data_id | INT AUTO_INCREMENT PRIMARY KEY | 主键 |
| symbol | VARCHAR(10) | 证券代码 |
| date | DATE | 日期 |
| price | DECIMAL(10,2) | 价格 |
5. 核心算法设计¶
1. 因子挖掘(Factor Mining)¶
目标:从多源异构数据中提取对投资决策有影响的关键因子。
1.1. 任务拆解:¶
| 子问题 | 数据处理 | 说明 |
| 文本语义分析 | LLM模型(如 GPT-4 / DeepSeek-V1) | 强大的上下文理解能力,可从新闻/公告中抽取与投资相关的因子(如“市场波动性上升”、“监管收紧”等) 并将其表达为(+1,-1)类的符号化因子 |
| Prompt设计 | 人工设计 / 自动生成prompt模板 | 模型需要精心设计prompt,引导其输出因子及影响方向(正/负) |
1.2. Prompt设计:¶
作为金融分析师,请从以下文本中提取影响资产价格的三个因子:
文本:{input_text}
输出:因子名称及其影响方向(+1/-1)。
- 输出:因子名称及其相关信息(如市盈率、市场情绪)。
1.3. 技术实现:¶
- 提示学习:调用预训练的大语言模型(如deepseek)。
2. 符号化规则(Symbolized Rules)¶
目标: 将原本复杂的数值关系或模型决策过程,转化为简单、清晰、具有明确逻辑的if-then形式规则,增强系统的可解释性、可追溯性与合规性。
2.1. 任务拆解:¶
| 子问题 | 数据处理 | 说明 |
| 规则提取 | 基于GBDT或决策树模型提取决策路径 | 通过建模结构化历史数据,学习特征与投资收益之间的关联,提取出明确条件 |
| 规则转化 | 将决策路径标准化为if-then格式 | 将模型内部隐含的路径条件,转化为符号化表达,供后续使用和展示 |
2.2. 技术实现:¶
-
基础模型选择
- 使用GBDT(Gradient Boosting Decision Tree或单棵决策树(CART对历史数据建模。
- 输入特征包括财务指标与用户画像(风险偏好、年龄段等)。
- 输出标签为投资结果,如“收益率高于平均水平”、“波动率低”等。
2.3. 规则提取过程¶
- 训练完成后,从每棵决策树中遍历所有叶子节点,记录到达每个叶子的路径条件。
- 每一条路径对应一个if-then规则,形式为:
IF (市盈率 < 12) AND (ROE > 15%) THEN 高收益
- 路径中的每一个节点条件都被保留,用作规则前提。
2.4. 符号化标准输出¶
每条提取规则同一转化标准的JSON格式,示例如下:
{
"rule_id": "RULE_001",
"conditions": [
{"feature": "市盈率", "operator": "<", "threshold": 12},
{"feature": "ROE", "operator": ">", "threshold": 15}
],
"prediction": "高收益",
"confidence": 0.82
}
其中:
rule_id:规则唯一编号conditions:满足该规则的条件集合prediction:规则推断的投资结果confidence:依据训练样本计算的规则置信度
3. 因子融合与决策生成(Factor Fusion and Decision Making)¶
目标:
将不同来源挖掘得到的各类因子进行有效融合,建立统一的因子池,综合评估各资产,输出个性化投资建议和决策支持。
3.1. 任务拆解:¶
| 子问题 | 数据处理 | 说明 |
| 因子标准化 | 统一各因子的数据表示与方向性 | 将因子转化成统一格式,便于后续处理 |
| 因子重要性评估 | 计算每个因子的权重或得分 | 根据因子的历史表现、模型评估结果赋予不同权重 |
| 决策打分建模 | 综合各因子信息生成资产得分 | 使用简单模型或打分函数综合各因子得分,完成资产推荐排序 |
3.2. 技术实现:¶
3.2.1. 因子标准化处理¶
- 将所有提取到的因子整理成统一格式:
| 因子名称 | 因子类型 | 来源 | 方向(+1/-1) | 重要性得分(可选) |
| 市盈率<12 | 符号化规则因子 | 结构化数据 | +1 | 0.42 |
| 市场情绪上升 | 文本因子 | LLM抽取 | +1 | 0.35 |
| 行业监管趋严 | 文本因子 | LLM抽取 | -1 | 0.28 |
- 统一因子描述方式,确保在后续建模中可以直接读取。
3.3. 因子重要性评估¶
- 依据GBDT特征重要性(Feature Importance)或者因子出现时,模型得分上升程度打分
- 最终得到每个因子的权重(importance score),用于决策时加权处理。
3.4. 决策打分建模方法¶
方法:简单线性加权打分(适合首版系统)
- 定义每个资产的综合得分(Score):
$$ \text{Score(asset)}=\sum_{i=1}^{N}(w_{i}\times I_{i}) $$ 其中:
- \(w_{i}\):第 \(w_{i}\) 个因子的权重(importance)
- \(I_{i}\):资产是否符合第
 个因子,符合为1,不符合为0。即一个指示变量
个因子,符合为1,不符合为0。即一个指示变量 - 按得分高低,对资产进行排序,推荐得分最高的资产组合给用户。
3.5. 结果解释与输出¶
- 推荐列表中每个资产附带对应的推荐理由:
示例:
推荐资产A:因为符合"市盈率低于12"、"市场情绪指数上升"、"风险偏好匹配成长型"等因子,预计未来收益潜力较好。
- 推荐理由可以直接来源于因子触发记录,也可以调用大语言模型(如DeepSeek)根据因子集合生成自然语言解释,提升用户体验。
小组成员¶
| 学号 | 姓名 |
|---|---|
| 231275036 | 朱晗 |
| 231275033 | 陈俊凯 |
| 231275019 | 欧阳慧婷 |
| 231275011 | 杨惠文 |