动态规划 DP¶
框架 - Basic Idea of Dynamic Programming(DP) - Smart scheduling of subproblems - Minimum Cost Matrix Multiplication - BF1, BF2 (Brute Force) - A DP solution - Weight Binary Search Tree
Subproblem Graph¶
- 一个递归算法 \(A\) 的 子问题图 定义如下:
- vertex: the instance of the problem
- directed edge: \(I\to J\) if and only if when \(A\) invoked on \(I\), it makes a recursive call directly on instance \(J\).
- Portion \(A(P)\) of the subproblem graph for Fibonacci function: here is fib(6)

拓扑序¶
Fibonacci 可以拉成一个拓扑序(因为是有向无环图), 即
以拓扑排序展示同一个图,所有的节点按照其完成时间的逆序被排成从左向右的一条水平线,所有边都是从左指向右。见vault/redkoldnote/docs/本科课程/算法设计与分析/Notes/图#构造逆拓扑序
我们的动态规划思路,就是利用 子问题图,减少重复计算(依靠记忆功能)
Basic Idea of DP¶
- Smart recursion
- Compute each subproblem only once
-
Basic process of a "smart" recursion
可以说,DP 就是一种新概念递归
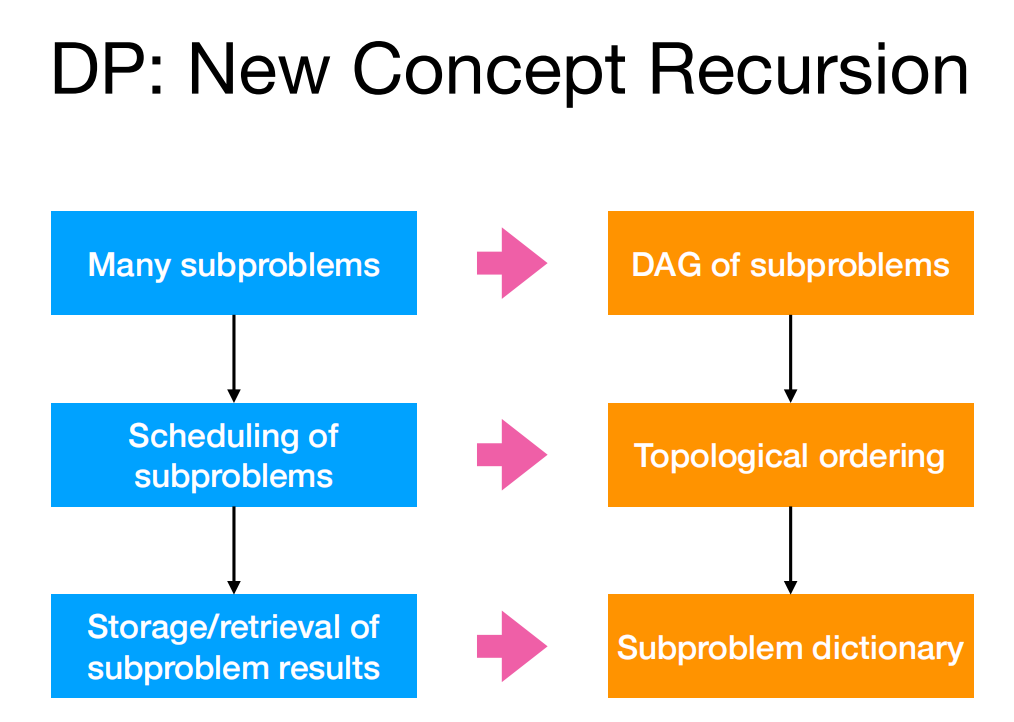
矩阵连续乘法 DP 问题(Matrix Multiplication)¶
问题描述¶
- The task
- Find the product: \(A_{1}\times A_{2}\times\dots A_{n-1}\times A_{n}\)
- \(A_{i}\) is 2-dimensional array of different legal sizes
-
The issues
- Matrix multiplication is associative
- Different computing order results in great difference in the number of operations
- The problem:
- Which is best computing order
-
简单描述问题代价:
- 令 \(C=A_{p\times q}\times B_{q\times r}\)
- 考虑 \(C\) 中的每个元素 \(c_{ij}=\sum_{k=1}^{q}a_{ik}b_{kj}\)
- 而 \(C\) 有 \(p\times r\) 个 \(c_{ij}\) 这样的元素
- 所以总共 \(pqr\) 次乘法。这就是代价。
所以我们关注代价,只需要关注每个矩阵的 维度 情况
从维度角度,问题补充描述如下:
- 矩阵:\(A_{1},A_{2},\dots,A_{n}\)
- 维度:dim: \(d_{0},d_{1},d_{2},\dots,d_{n-1},d_{n}\), for \(A_{i}\) is \(d_{i-1}\times d_{i}\)
- 子问题序列:\(seq:s_{0},s_{1},s_{2},\dots,s_{k-1},s_{len}\)
- 含义:代表 \(k\) 个矩阵的乘法,相当于一个计算顺序。
- 初始状态下,原问题为:\(seq=(0,1,2,\dots,n)\)
- 即问题还没有开始计算,你可以选择从 0 到 n 选择一个开始算。
直觉尝试 1¶
def mmTry1(dim,len,seq):
if(len<3):
bestCost=0
else:
bestCost=+inf
for(i=1;i<= len-1;i++):
c=cost of multiplication at position seq[i]
newSeq=seq with i th element deleted;
b=mmTry1(dim,len-1,newSeq)
bestCost=min(bestCost,b+c)
return bestCost
- 分析
- \(T(n)=(n-1)T(n-1)+n\), \(T(n)\in \Theta((n-1)!)\)
- 这个算法的本质是
- 对于每一步先算哪个,采用遍历
seq的方式来做。 - 由于选择了先算某个相邻矩阵 \(s_{i}\) 之后,序列将会发生变化,具体而言会去掉一个维度,之后的运算代价会变。所以 递归地 来算之后的代价。
- 对于每一步先算哪个,采用遍历
- 最后总体是最优的。
直觉尝试 2¶
另一种直觉尝试是 2 分的来做,但是仍然是指数级别
def mmTry2(dim,low,high):
if(high-low==1):
bestCost=0
else:
bestCost=inf
for k in range(low+1,high):
a=mmTry2(dim,low,k)
b=mmTry2(dim,k,high)
c=cost of multiplication at position k
bestCost=min(bestCost,a+b+c)
return bestCost
聪明的递归 DP 3 (基于 2)¶
- 利用
DFS的思想,可以在 \(O(n^{3})\) 时间内遍历子问题图
def mmTry2DP(dim,low,high,cost):
...
for k in range(low+1,high):
#如果没有存过这个代价,就算一次
if(member(low,k)==false):
a=mmTry2(dim,low,k);# 和DFS类似,相当于看一下white节点
else:
a=retrieve(cost,low,k)
if(member(k,high)==fasle):
b=mmTry2(dim,k,high)
else:
b=retrive(cost,k,high)
...
#存储代价
store(cost,low,high,bestCost)
return bestCost
计算顺序¶
考虑我们的 子问题 的依赖关系 - 计算 \(A[low,high]\),一定要利用到 \(low<k<high\),计算 \(A[low,k]\) 和 \(A[k,high]\) - 所以我们要设计一种 计算顺序,使得算到 \(A[low,high]\) 的时候,依赖的子问题已经算过了。 - 从这个思路来说,我们应该先算 \(low\) 更大的,\(high\)更小的,计算顺序不唯一。 - 可以从下往上,从左往右计算 如图 ![[matrix-multi-order-pic.png]]
list matrixOrder(n,cost,last):
for(low=n-1; low>=1; low--){
for(high=low+1; high<=n; high++){
计算子问题的解,存在cost[low][high]中和last[low][high]中
}
}
return cost[0][n];
总体时间复杂度分析¶
- 子问题个数
- \(low<high\), 共有 \(O(n^{2})\) 种组合, 子问题规模 \(O(n)\)
- 每个子问题代价
- 最优解要遍历考虑 \(O(n)\) 种可能性
- 总体复杂度
- 由上面,不难知道是 \(O(n^{3})\)
总结算法¶
数据结构分析:
- DimeList: 记录维度
- cost[i][j] 记录从 i 到 j 的矩阵计算的最小代价
- last[low][high]: 记录 (low,high) 这一子问题最优相乘中 最后一次相乘的位置
def matrixMultDP(DimeList[0..n]):
for high = low+1 to n do:
if high-low ==1 then:
bestCost=0
bestLast=-1
else:
bestCost=+inf
for k=low+1 to high-1 do:
a=cost[low][k]
b=cost[k][high]
# 最后一次计算的代价d_low*d_k*d_high,DimeList是维度数组
c=multCost(DimeList[low],
/DimeList[k],DimeList[high])
if a+b+c < bestCost then:
bestCost=a+b+c
bestLast=k
cost[low][high]=bestCost
last[low][high]=bestLast
extractOrder();
return cost[0][n]
def extractOrder():
multNext=0
#初始化队列存储相乘顺序
queMultOrder.init()
extract(0,n)
def extract(low,high):
if high-low >1 then:
k=last[low][high]
# 后序遍历,因为先做内层子问题,外层才能算。
extract[low][k]
extract[k][high]
queMultOrder.push(k)
最优二叉搜索树问题 Optimal Binary Tree¶
一个二叉搜索树的节点存放搜索的 Key,其有出现的 频率\(p_{i}\),一个词搜索代价为 \(p_{i}c_{i}\),即搜索的频率乘上搜索它需要的 steps,体现为二叉树的深度。
问题描述¶
- Key 被排好序,且每个 key \(K_{i}\),都指派一个权重 \(p_{i}\)
- 每个子问题可以被划分为 \((low,high)\)
- The subproblem \((low, high)\) is to find the binary search tree with minimum weighted retrieval cost.
状态转移方程¶
- \(p(low,high)\): 等于 \(\sum_{i=low}^{high}p_{i}\),也就是子问题 \((low,high)\) 的权重
- \(A[low,high,r]\):记录子问题 \((low,high)\) 在当以 \(K_{r}\) 作为搜索树的
root的时候的最低搜索代价(minimum weighted retrieval cost)- 考虑这个子问题,可以递归的设计,即左子树代价+右子树代价+本层搜索权重
- \(A(low,high,r)=p(low,high)+A(low,r-1)+A(r+1,high)\)
- 依赖于 higher first index,更大的列
- 依赖于 lower second index,更小的行
- 依赖这个来设计计算顺序
- \(A[low,high]\): 记录对于搜索选择
root的所有情形的最小值。- 自然有 \(A[low,high]=\min\{ A(low,high,r)|low\leq r \leq high \}\)
数据结构与 DP 思路¶
- Array
cost[][]- 给出子问题 \((low,high)\) 的代价
cost[low][high] - The
cost[low][high]depends upon subproblems with higher first index (row number) and lower second index (column number)
- 给出子问题 \((low,high)\) 的代价
- Array
root[][]- 给出子问题 \((low,high)\) 的最优选择根
root其实和矩阵乘法设计顺序非常类似。
- 给出子问题 \((low,high)\) 的最优选择根
算法¶
![[Pasted image 20250513171212.png]] 在 \(\Theta(n^{3})\) 内'
编辑距离问题(edit distane revised)¶
编辑距离(Edit Distance)问题是经典的字符串处理问题,主要用于衡量两个字符串之间的相似性。编辑距离定义为将一个字符串转换为另一个字符串所需的最少操作次数,允许的操作包括:
1. 插入一个字符
2. 删除一个字符
3. 替换一个字符
动态规划解决编辑距离问题的知识框架¶
1. 定义状态¶
设 dp[i][j] 表示将字符串 A[0...i-1] 转换为 B[0...j-1] 的最小编辑距离。
2. 状态转移方程¶
根据当前字符的相同或不同,状态转移分为以下几种情况:
- 当 A[i-1] = B[j-1]: 也就是最后一位相同
dp[i][j] = dp[i-1][j-1](无需额外的操作,直接递归到子问题)
- 当 A[i-1] != B[j-1]:
dp[i][j] = min(dp[i-1][j-1], dp[i-1][j], dp[i][j-1]) + 1
其中:
- dp[i-1][j-1] + 1:替换操作 (建立在不相等的情况下)
- dp[i-1][j] + 1:删除操作
- dp[i][j-1] + 1:插入操作
借助 indicative variable,可以简化表述。
从后缀视角考虑
$$
c[i][j]=\begin{cases}
1+c[i-1][j] \
1+c[i][j-1] \
I_{A\neq B}+c[i-1][j-1]
\end{cases}
$$
where \(I_{A\neq B}=1\iff A\neq B,else=0\)
3. 初始化¶
dp[0][j] = j:将空字符串转换为B[0...j-1]需要插入j个字符。dp[i][0] = i:将A[0...i-1]转换为空字符串需要删除i个字符。
4. 目标值¶
dp[m][n],其中 m 和 n 分别是 A 和 B 的长度。
5. 时间和空间复杂度¶
- 时间复杂度:
O(m × n) - 空间复杂度:
O(m × n),可优化为O(min(m, n))通过滚动数组。
从 DP 视角看算法¶
Floyd 算法¶
Floyd算法参考 其中本质的 DP 状态转移方程就是 ![[Pasted image 20250515103051.png]] $$ dist(u,v,r)=\begin{cases} w(u\to v) & \text{if \(r=0\)} \ \min{ dist(u,v,r-1),dist(u,r,r-1)+dist(r,v,r-1) }&\text{otherwise} \end{cases} $$
重新理解 DP¶
DP 的本质¶
DP,即 Dynamic Programming. 从实际意义来说,称作 Dynamic Planning 或者 Smart Planning 也不错。 其核心,也就是 Smart 的地方在于: - Brute Force+Memory re-use - 即 DP本质是一种有控制的(Controlled)蛮力求解,即规划了一个合理的计算顺序。
抽象出子问题¶
我们通常尝试找到一种 plannning/scheduling, 满足类似这样的 状态转移方程 $$ =\min/\max{ a_{1},a_{2},\dots a_{n} } $$
即,我们希望找到一个 拓扑依赖关系,这样就能规划出一个计算顺序,使得依赖的子问题在之前都被计算过。具体是因为拓扑关系是可以在数轴上拉成单向的图#拓扑序
抽象出来的解决问题的图,点和边的意义: - 点:代表 subproblem - 边:代表 guess related problem 依赖关系 - 常见的,如选/不选,在 \(\{ 1,2,3\dots \}\) 中选 1 个
子问题特征如何划分,在这个划分拓扑图的意义上,非常重要。
以最大递增子序列为例子¶
- 我们的问题有很多特征,拿 最长递增子序列(Longest Increasing Subsequence)来说,单纯的划分子问题为 \(LIS[i]\)(表达前 \(i\) 位能形成的最大递增子序列的长度),即只有一个维度的空间,并不能完成正确的问题依赖。 这是因为,从 \(LIS[i]\) 依赖 \(LIS[i-1]\) 来看,不确定其变化情况。即可能新加的字母 \(a\) 和前 \(i-1\) 位的其他部分,能形成更长的递增子序列。
- 所以我们需要别的信息,自然地想到,递增子序列的变化,应该只依赖之前的递增子序列(subproblem)最后一位是什么
-
所以构造新的 \(LIS[i]\),
- 记录以第 \(i\) 个元素为结尾的最大连续子序列的长度
-
状态转移方程: $$ LIS[i]= \max_{j
for循环,即先遍历所有不同的结尾 \(j\),找出最大值。
由于我们并不确定最大连续子序列以 哪一位作为结尾,所以最后我们遍历 \(LIS\) 数组找出最大值即为所求。
考虑其他子序列问题,触类旁通¶
例如
- 最大连续子序列和问题,也可以考虑除了位置特征,还需要加什么特征作为状态转移的依据?
- 思考,也可以添加一个量,即 \(dp[i]\) 返回一个 pair,即前 \(i\) 位的最大连续子序列和的大小 \(sum\) 和其是否以最后一位结尾。
- 引入 是否以最后一位结尾,是因为这直接反映 连续 这一条件的依赖关系。
- 有一个习题:
找零钱问题¶
未命名文件夹/redkoldnote/docs/算法设计与分析/作业/assignment6/231275036 朱晗 作业6#考虑零钱兑换问题的各种变体