classSolution { private: constint MOD = 1000000007; public:
intgetAns(int left,int right,vector<int>& powers){ int cur=1; for(int i=left;i<=right;i++){ cur = static_cast<longlong>(cur) * powers[i] % MOD; } return cur; }
vector<int> productQueries(int n, vector<vector<int>>& queries){ // use binary to express n vector<int> powers; vector<int> ans; int tmp=n; int bitnum=1; while(tmp){ if(tmp%2){powers.push_back(bitnum);} bitnum*=2; tmp=tmp>>1; }
for(int i=0;i<queries.size();i++){ int res_i=getAns(queries[i][0],queries[i][1],powers); ans.push_back(res_i); }
classSolution { public: longlongminOperations(vector<vector<int>>& queries){ int n = queries.size(); longlong ans=0; for (int i = 0; i < n; i++) { vector<int> query=queries[i]; int l=query[0]; int r= query[1]; // 0-3 need 1 // 4-15 need 2 // 16-4^3-1 need 3 longlong mybase=4; longlong cnt=1; longlong sum=0; while(mybase <= l){ cnt++; mybase<<=2; } // l need to do cnt times to get 0; while(mybase<=r){ // mybase is 4^cnt, numbers from 4^(cnt-1) to 4^cnt-1 need divide 4 for cnt times to get to 0 // so it's mybase-1 - l +1 , base -l // it's well defined. the first l is also fit this. sum+=(longlong)(mybase-l)*cnt; l = mybase; mybase <<=2; cnt++; // cnt++; }
// tail situation // now l<=r<mybase, we neet to count (r-l+1)*cnt sum+=(r-l+1)*cnt; ans+=(sum+1)/2;
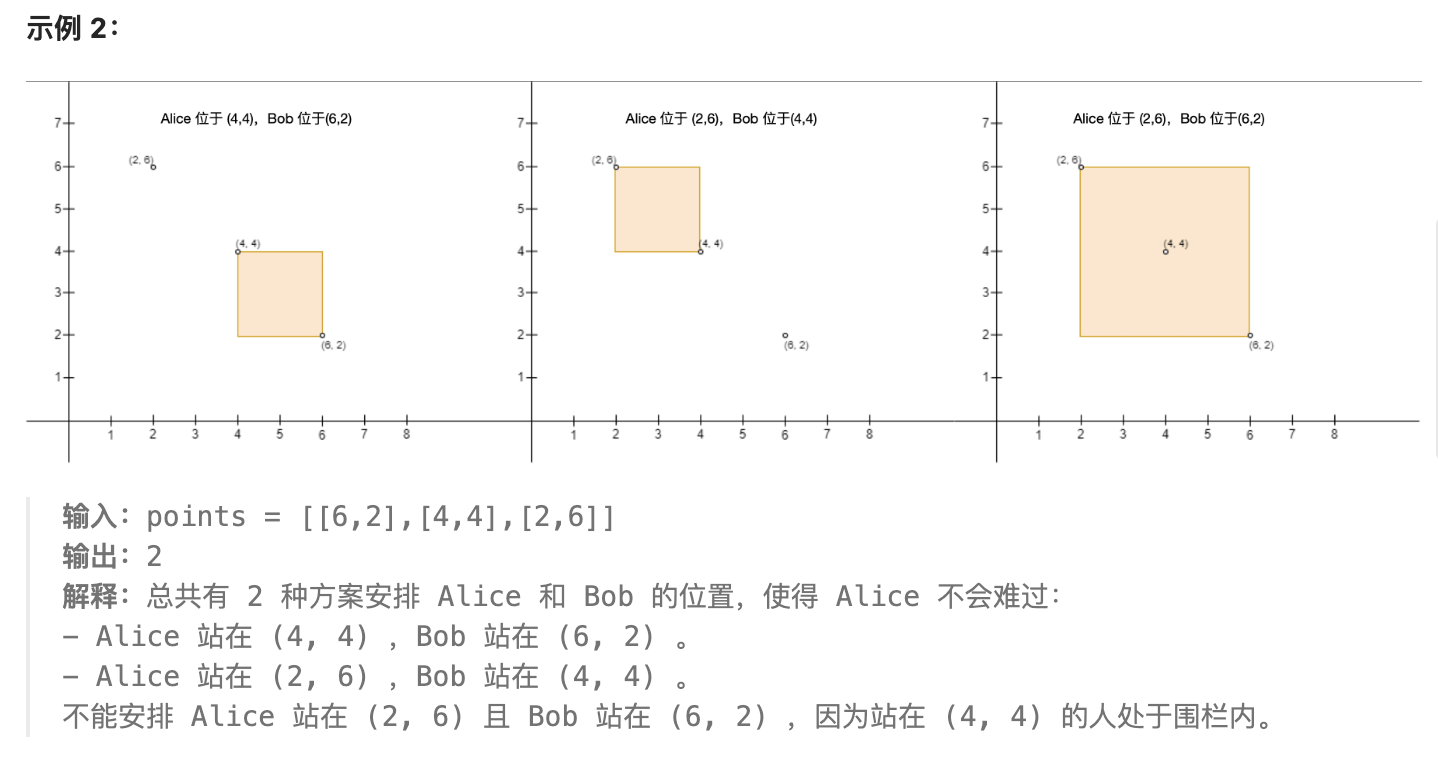
给你一个 n x 2 的二维数组 points ,它表示二维平面上的一些点坐标,其中 points[i] = [xi, yi] 。
我们定义 x 轴的正方向为 右 (x 轴递增的方向),x 轴的负方向为 左 (x 轴递减的方向)。类似的,我们定义 y 轴的正方向为 上 (y 轴递增的方向),y 轴的负方向为 下 (y 轴递减的方向)。
你需要安排这 n 个人的站位,这 n 个人中包括 Alice 和 Bob 。你需要确保每个点处 恰好 有 一个 人。同时,Alice 想跟 Bob 单独玩耍,所以 Alice 会以 Alice 的坐标为 左上角 ,Bob 的坐标为 右下角 建立一个矩形的围栏(注意,围栏可能 不 包含任何区域,也就是说围栏可能是一条线段)。如果围栏的 内部 或者 边缘 上有任何其他人,Alice 都会难过。
classSolution { public: intnumberOfPairs(vector<vector<int>>& points){ std::sort(points.begin(), points.end(), [](const vector<int>& a, const vector<int>& b) { if (a[0] != b[0]) return a[0] < b[0]; // x 升序 return a[1] > b[1]; // y 降序 });
// Alice is left-up: x1<=x2, y1>=y2 // for x is sorted increasingly, we hold x1<=x2
// and no others- condition // it means points whose index in [i+1,j-1], their yx must >y1 or <y2, so won't bother Alice and Bob // we maintain a max_Y as the maximum y indexd from i+1 to j-1. int n = points.size(); int ans = 0; for (int i = 0; i < n; i++) { int y1 = points[i][1]; int max_Y = INT_MIN; for (int j = i + 1; j < n && max_Y < y1; j++) { int y2 = points[j][1]; if(y2<=y1 && y2>max_Y){ max_Y=y2; ans++; } } } return ans; } };
分析
本题采用模拟就比较容易做
模拟需要考虑
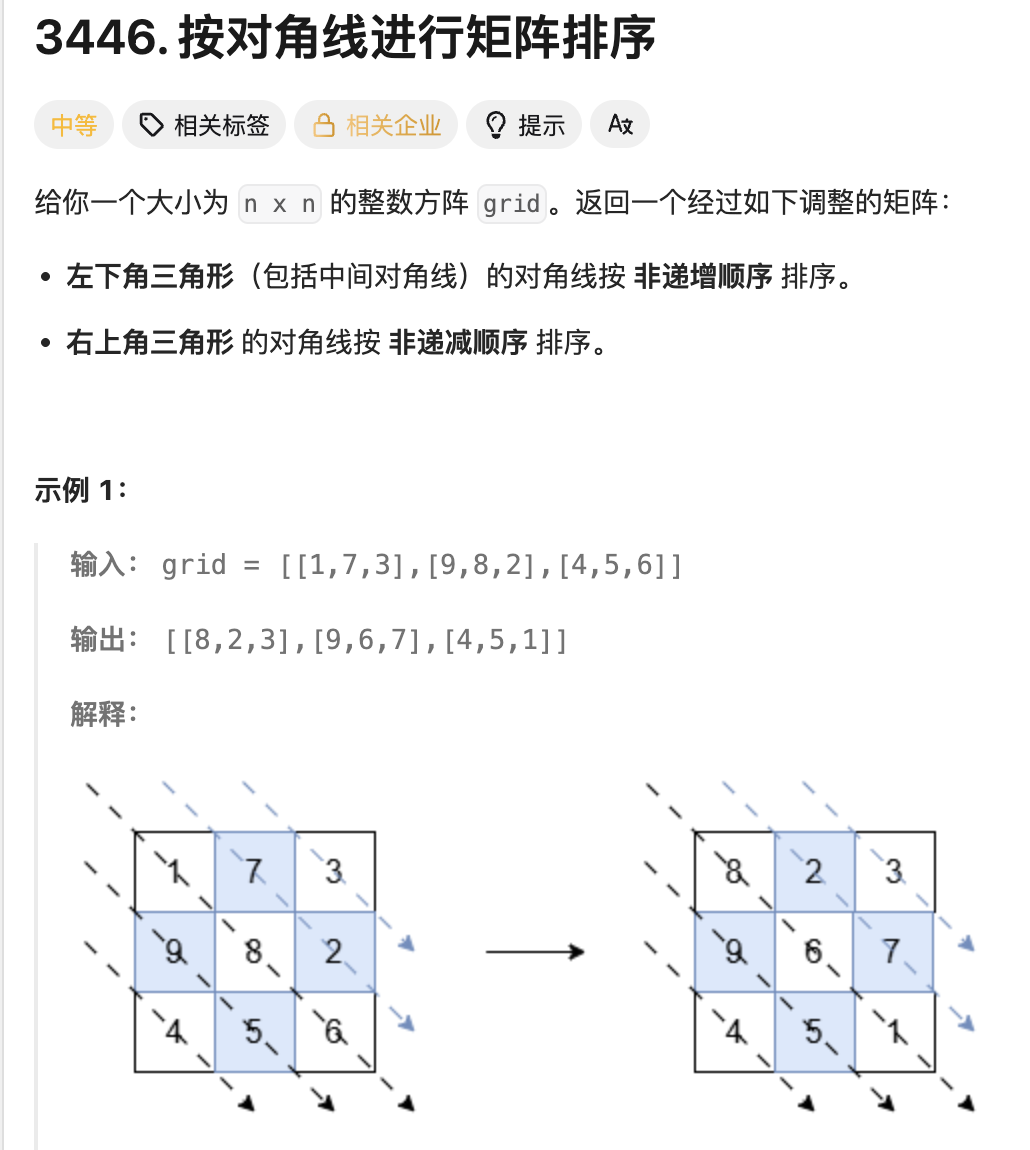
怎么取出对角线的元素?
排序完,怎么放回去?
究其根本是 如何遍历对角线的问题
对于左下的,可见其都从 j=0 开始,我们可按行遍历,且每次 j 增加都意味着 i 增加,即坐标为 (i+j,j), 且满足 i+j<n
classSolution { public: boolisValidSudoku(vector<vector<char>>& board){ // create a hash map. it contains 1-9 numbers appear times cnt; int rows[9][9]; int cols[9][9]; int subboxes[3][3][9];
classSolution { public: string convert(string s, int numRows){ if(numRows ==1 ||s.size()<numRows){ return s; } vector<string> rows(numRows); int curRow=0; int goingDown=true;
for(char c:s){ rows[curRow]+=c; // add char at some line; curRow+=goingDown?1:-1; // we don't actually care about the "space" in a line, we only care about the char in a row if(curRow==numRows-1 || curRow==0){ goingDown=!goingDown; } } string ans; for(auto str:rows){ ans+=str; } return ans; } };
classSolution { public: using ll = longlong; longlongminTime(vector<int>& skill, vector<int>& mana){ int n = skill.size(); int m = mana.size(); vector<ll> times(n); for(int j=0; j < m; j++){ // cur_time: one iteration, our cost of time ll cur_time=0; // all the people before n-1 wizzar have done. for(int i = 0; i < n; i++){ cur_time = max(cur_time, times[i]) + skill[i] * mana[j]; // the first potion is all the time add up. // and we can use this potion's time to calculate the finish time time[i][j] for each wizzar i } // times[i] at the first loop is all 0; times[n-1] = cur_time;
constint INF = 0x3f3f3f3f; classSolution { private: int n;
intgetMyMax1(int i, int j, const vector<vector<int>>& dp){ int m=dp[i-1][j]; if(j-1>=0 && dp[i-1][j-1]>m){m=dp[i-1][j-1];} if(j+1<n && dp[i-1][j+1]>m){m=dp[i-1][j+1];} return m; }
intgetMyMax2(int i, int j, const vector<vector<int>>& dp){ int m=dp[i][j-1]; if(i-1>=0&&dp[i-1][j-1]>m){m=dp[i-1][j-1];} if(i+1<n&&dp[i+1][j-1]>m){m=dp[i+1][j-1];} return m; }
public: intmaxCollectedFruits(vector<vector<int>>& fruits){ n = fruits.size(); int res = 0;
// 主对角线 for (int i = 0; i < n; ++i) { res += fruits[i][i]; fruits[i][i]=0; }
classSolution { public: longlongminCost(vector<int>& basket1, vector<int>& basket2){ int m = INT_MAX; unordered_map<int, int> frequency; // find the minimum element in both baskets and count the frequency of each element for (int x1 : basket1) { frequency[x1]++; m=min(m, x1); } for (int x2 : basket2) { frequency[x2]--; m=min(m, x2); }
longlong ans = 0;
vector<int> to_be_swap; // 记录需要交换的元素 // 交换是什么样的?比如basket 1 成本为4的有x个,basket 2 成本为4的有y个,应该保证多的那个交换(x-y)/2个。 for (auto [k, c] : frequency) { if (c % 2 != 0) return-1; // If any element has an odd frequency,then can't divide into 2 basket, return -1 for(int i = 0; i < abs(c/2); i++) { to_be_swap.push_back(k); } }
// 将to_be_swap中的元素排序 // 我们将成本较小的元素放在前面,这样可以最小化总成本,交换前一半即可。 // 需要注意每个元素交换不一定只交换一次,可以以最小元素m为跳板交换两次达到效果。需要比较2m和每个元素的成本 sort(to_be_swap.begin(), to_be_swap.end()); for (int i = 0;i<to_be_swap.size()/2;i++) { ans += min(to_be_swap[i], 2 * m); } return ans; } };
classSolution { public: intminimumSubarrayLength(vector<int>& nums, int k){ // or: a | b >= a, or b int n=nums.size(); int ret=INT_MAX; // 计算所有子数组的OR并记录下来 for(int i=0;i<n;i++){ int x=nums[i]; if(x>=k) return1; // we now calculate the j from i-1 to 0. update it as the ORs from j to i in original nums
for(int j=i-1;j>=0 ;j--){ if((nums[j] | x )== nums[j]){ break; } // nums[j] = OR all the nums[j+k], where j+k <i nums[j] |=x; if(nums[j]>=k){ // or is non-decrease. ret= min(ret, i-j+1); } } } return ret==INT_MAX? -1 : ret; } };
classSolution { public: vector<int> smallestSubarrays(vector<int>& nums){ int n=nums.size(); vector<int> ans(n); // get the max or value
for (int i = 0; i < nums.size(); i++) { int x = nums[i]; int j = i - 1; ans[i]=1; for (j = i - 1; j >= 0; j--) { // if x subset nums[j], then [0, i], cannot find larger or value if((nums[j] | x) == nums[j]){ break; } nums[j] |= x;
int farthest = *max_element(last.begin(),last.end()); // if farthest is -1, it means right has no any 1 bit. or is 0. shortest ans is 1 ans[i]=farthest!=-1 ? farthest-i+1 : 1; } return ans; } };
#include<iostream> #include<vector> #include<numeric> #include<algorithm> #include<cmath> #include<cstring>// For memset, though std::vector is preferred #define endl "\n"
usingnamespace std;
// N 应该略大于最大可能的元素数量 constint N_MAX = 200005;
// a 数组为原始数据数组 int a[N_MAX]; // sum 数组记录前缀和数组 (使用 long long 防止溢出,尽管元素值较小) longlong sum[N_MAX];
// b 数组为 a 中值不为 1 的元素所构成的数组 int b[N_MAX]; // id[i] 表示在 b 数组中下标为 i 的元素原始下标 (在 a 数组中的下标) int id[N_MAX];
// L1[i] 存储紧邻 i 左侧的连续 '1' 的数量 int L1_count[N_MAX]; // R1[i] 存储紧邻 i 右侧的连续 '1' 的数量 int R1_count[N_MAX];
int n; longlong ans = 0; int blen = 0;
voidsolve(){ // 1. 输入和预处理前缀和 if (!(cin >> n)) return; ans += n; // 每个单独元素 (i=j) 都是一个答案 (因为 a[i] == a[i])
for (int i = 1; i <= n; i++) { cin >> a[i]; sum[i] = sum[i - 1] + a[i];